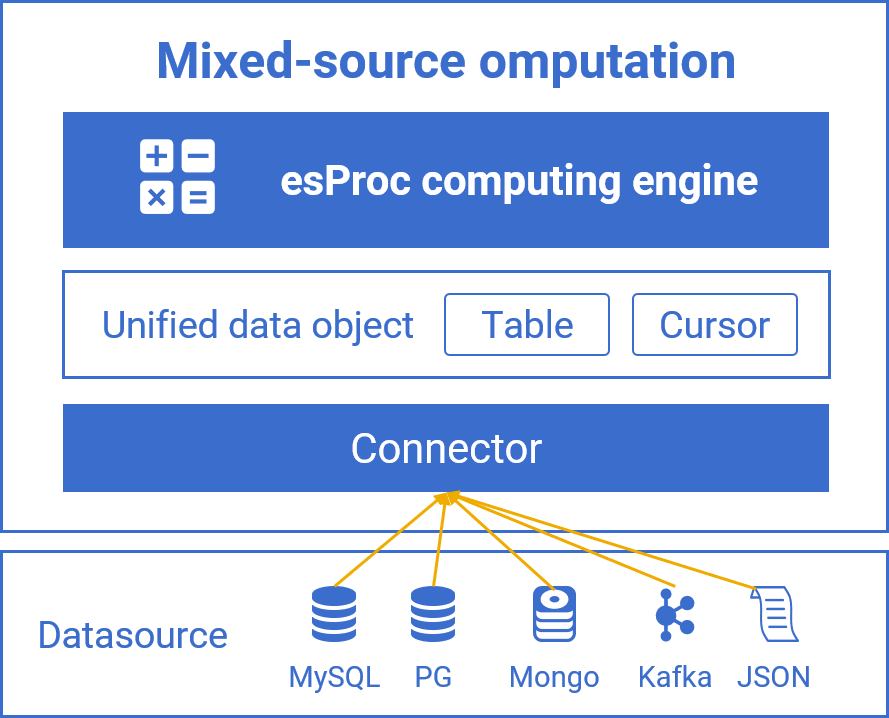
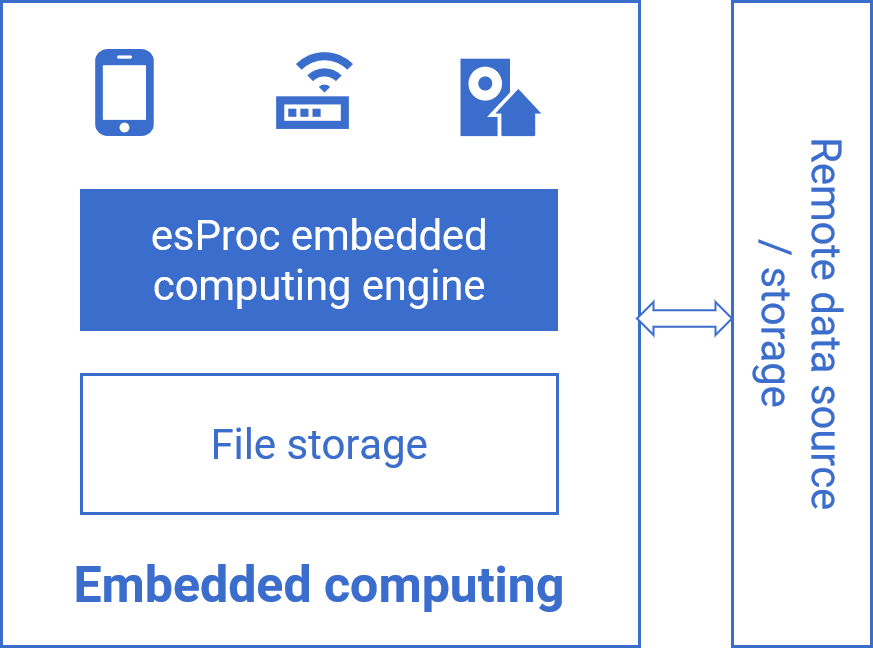
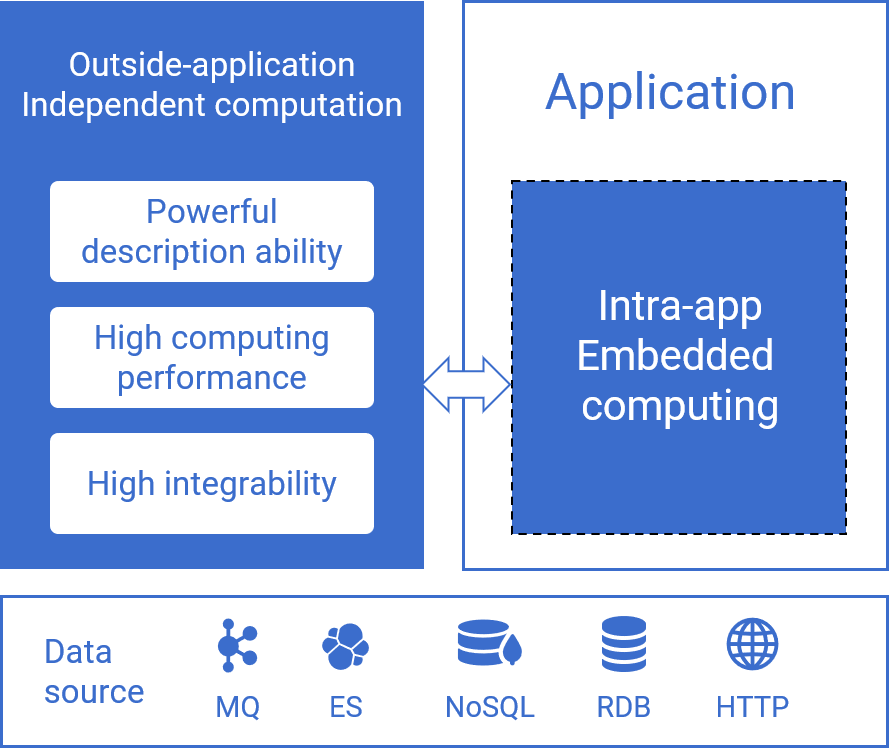
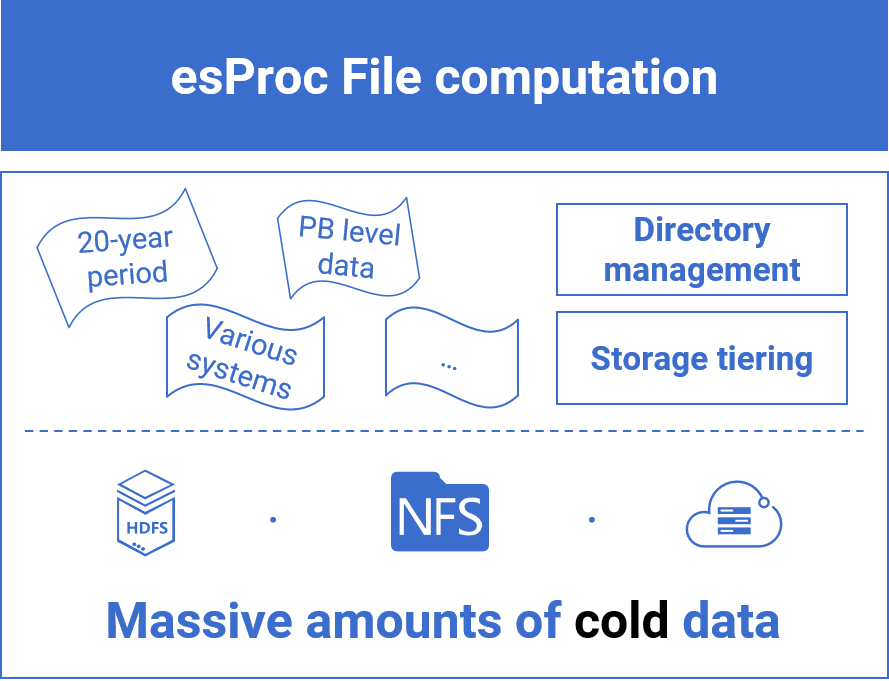
SQL-basedJava-basedPython-based
SQL-basedJava-basedPython-based
pos@z("abcdeffdef","def") //@z: backwards searching
pos@c("abcdef","Def") //@c: Case insensitive
pos@zc("abcdeffdef","Def") //Options working together
//The three-level parameter: first level represented by semicolon, second level represented by comma, and third level represented by colon
join(Orders:o,SellerId;Employees:e,EId).groups(e.Dept;sum(o.Amount))
//Implicit Lambda syntax, further simplified by symbols [] # ~
stock.sort(tradeDate).group@i(price< price[-1]).max(~.len())
// Position searching and relative reference of position stock.calc(stock.pselect(price>100),price-price[-1])
// Further computations on each member subset of group
T("employee.csv").group(DEPT).select(~.len()>10).conj()
//Directly use dot(.)to reference data at a lower level
json(file("orders.json").read())orders.select(order_details.select@1(product.category=="Electronics") && order_details.sum(price*quantity)>200).new(order_id,order_date)
public Map<String, Integer> calculateMaxConsecutiveIncreaseDays(List<StockRecord> stockRecords) {
Map<String, List<StockRecord>> groupedByCode = stockRecords.stream()
.collect(Collectors.groupingBy(
StockRecord::getCode,
Collectors.collectingAndThen(
Collectors.toList(),
list -> {
list.sort(Comparator.comparing(StockRecord::getDt));
return list;
}
)
));
Map<String, Integer> result = new HashMap<>();
for (Map.Entry<String, List<StockRecord>> entry : groupedByCode.entrySet()) {
String code = entry.getKey();
List<StockRecord> records = entry.getValue();
if (records.isEmpty()) continue;
Map<Integer, Integer> consecutiveDaysMap = new HashMap<>();
int cumulativeSum = 0;
for (int i = 0; i < records.size(); i++) {
StockRecord current = records.get(i);
int flag;
if (i == 0) {
flag = 1;
} else {
StockRecord prev = records.get(i - 1);
flag = current.getCl() > prev.getCl() ? 0 : 1;
}
cumulativeSum += flag;
consecutiveDaysMap.merge(cumulativeSum, 1, Integer::sum);
}
int maxDays = consecutiveDaysMap.values().stream()
.max(Comparator.naturalOrder())
.orElse(0);
result.put(code, maxDays);
}
return result;
}
SELECT CODE, MAX(con_rise) AS max_increase_days
FROM (
SELECT CODE, COUNT(*) AS con_rise
FROM (
SELECT CODE, DT, SUM(updown_flag) OVER (PARTITION BY CODE ORDER BY CODE, DT) AS no_up_days
FROM (
SELECT CODE, DT,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY CODE, DT) THEN 0
ELSE 1 END AS updown_flag
FROM stock
)
)
GROUP BY CODE, no_up_days
)
GROUP BY CODE
Simport pandas as pd
stock_file = "StockRecords.txt"
stock_info = pd.read_csv(stock_file,sep="\t")
stock_info.sort_values(by=['CODE','DT'],inplace=True)
stock_group = stock_info.groupby(by='CODE')
stock_info['label'] = stock_info.groupby('CODE')['CL'].diff().fillna(0).le(0).astype(int).cumsum()
max_increase_days = {}
for code, group in stock_info.groupby('CODE'):
max_increase_days[code] = group.groupby('label').size().max() – 1
max_rise_df = pd.DataFrame(list(max_increase_days.items()), columns=['CODE', 'max_increase_days'])
stock.sort(DT).group(CODE;~.group@i(CL< CL[-1]).max(~.len()):mids)

| A | |
| 1 | =connect("mysql") |
| 2 | =A1.query@x("SELECT o.order_id, o.user_id, o.order_date, oi.product_id, oi.quantity, oi.price FROM orders o JOIN order_items oi ON o.order_id = oi.order_id WHERE o.order_date >= CURDATE() - INTERVAL 1 MONTH") |
| 3 | =mongo_open("mongodb://192.168.1.15:27017/raqdb") |
| 4 | =mongo_shell@d(A3, "{ 'find': 'products', 'filter': { 'category': { '$in': ['Tablets', 'Wearables', 'Audio'] } }}” ) |
| 5 | =A2.join@i(product_id,A4:product_id,name,brand,category,attributes) |
| 6 | =A5.groups(category;sum(price*quantity):amount) |

esProc offers two high-performance storage formats
Simple format, no need to define structure
Mixed row-based and columnar storage, support index, and need to define structure beforehand
//To get TopN from entire set,database engine will perform optimization to avoid big sorting
SELECT TOP 10 * FROM Orders ORDER BY Amount DESC
//For an intra-group TopN,database optimization is disabled by the nested query and can only turn to big sorting
SELECT * FROM (
SELECT *, ROW_NUMBER() OVER (PARTITION BY Area ORDER BY Amount DESC) rn
FROM Orders )
WHERE rn<=10
| A | B | |
| 1 | =file("Orders.ctx").open().cursor() | |
| 2 | =A1.groups(;top(10;-Amount)) | Get TopN from entire set |
| 3 | =A1.groups(Area;top(10;-Amount)) | GET TopN from each group |